基于Flink的實時商品推薦系統架構分析
一、引言
在電商、內容平臺和各類在線服務領域,個性化推薦系統已成為提升用戶體驗、增加用戶粘性和驅動業務增長的核心引擎。傳統的批處理推薦系統雖能分析歷史數據,但無法實時捕捉用戶瞬息萬變的興趣和行為,存在明顯的反饋延遲。Apache Flink作為一個開源的流處理框架,以其高吞吐、低延遲、精確的狀態管理和出色的容錯機制,為構建新一代實時推薦系統提供了理想的底層支撐。本文旨在對基于Flink的商品推薦系統進行全面的計算機系統分析,探討其架構設計、核心流程、關鍵技術與挑戰。
二、系統總體架構
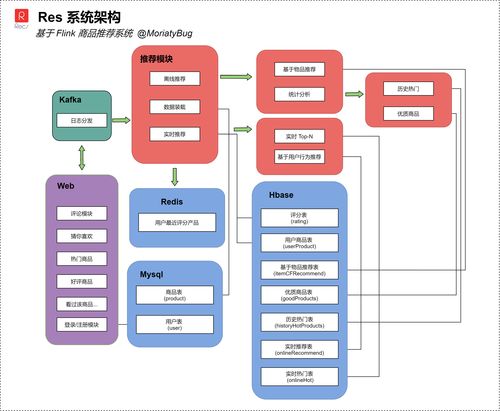
一個典型的基于Flink的實時推薦系統通常采用分層、模塊化的設計思想,整體架構可分為數據采集層、實時處理層、在線服務層和存儲層。
- 數據采集層:負責從各業務端(如APP、Web、服務器日志)實時采集用戶行為事件流,包括瀏覽、點擊、搜索、加購、購買等。常用工具包括Flume、Kafka Connector、或直接通過SDK將數據發送至消息隊列(如Apache Kafka)。Kafka作為高可靠的消息總線,起到了解耦和數據緩沖的作用。
- 實時處理層(Flink核心層):這是系統的“大腦”。Flink作業從Kafka消費原始事件流,進行一系列實時計算:
- 數據清洗與格式化:過濾無效數據,將異構數據轉換為統一的格式。
- 特征實時計算與更新:這是推薦算法的基石。Flink利用其狀態(State)管理能力,實時維護和更新用戶畫像(如近期興趣標簽、購買力)和商品畫像(如實時熱度、點擊率)。例如,通過滑動窗口統計過去一小時商品的點擊量。
- 實時匹配與排序:根據觸發事件(如用戶進入某個頁面),結合實時更新的用戶和商品特征,調用輕量級的召回模型(如基于實時協同過濾的相似商品召回)和排序模型(如實時CTR預估模型),在毫秒級內生成個性化推薦列表。模型本身可以通過在線學習(Online Learning)方式,由Flink流實時更新模型參數。
- 在線服務層:接收Flink處理層輸出的實時推薦結果(通常寫入高速緩存如Redis),并通過低延遲的RPC API(如gRPC、HTTP)向客戶端提供推薦服務。有時為了應對超高并發,該層還需承擔簡單的業務邏輯處理和結果融合(如將實時結果與離線推薦結果混合)。
- 存儲層:分為在線存儲和離線存儲。
- 在線存儲:使用Redis、Aerospike等內存數據庫,存儲需要極快讀寫的實時特征和臨時推薦結果。
- 離線/批處理存儲:使用HDFS、HBase、或數據湖(如Iceberg),存儲全量歷史數據,用于訓練更復雜的離線模型、進行深度數據分析以及作為Flink狀態故障恢復的備份。
三、核心處理流程與Flink應用
在Flink作業內部,數據處理流程是一個有向圖,主要涉及以下幾個關鍵算子:
- Source:從Kafka主題消費用戶行為事件流,構成DataStream。
- 實時特征工程:
- 用戶行為序列構建:使用
KeyedStream按用戶ID分區,結合ProcessFunction和狀態(ValueState或ListState)維護用戶近期的行為序列,用于實時序列推薦。
- 統計型特征計算:使用
Window操作(如滑動窗口、會話窗口)對商品或類目進行聚合計算(計數、求和),得到實時熱度、點擊率等特征。Flink的窗口機制和事件時間處理保證了在亂序數據流中計算的準確性。
- 模型推理與更新:
- 對于已部署的深度學習排序模型,可以通過Flink的異步I/O功能,并發地查詢外部特征庫(如Redis)獲取特征,并調用TensorFlow Serving或自研的模型服務進行實時推理。
- 對于在線學習場景,可以將(用戶特征,反饋結果)作為訓練樣本流,通過Flink的
CoMapFunction或自定義算子,逐步更新一個輕量級模型(如邏輯回歸、FTRL)的參數,并實時將新參數同步到在線服務。
- Sink:將處理后的實時推薦列表、更新后的特征或模型參數,寫入到下游系統,如Redis(供在線服務讀取)、Kafka(用于其他系統訂閱)或數據庫。
四、關鍵技術考量與挑戰
- 狀態管理與容錯:推薦系統的狀態(用戶畫像、實時計數)至關重要。Flink提供了強大的狀態后端(如RocksDB)和基于Chandy-Lamport算法的精確一次(Exactly-Once)容錯保證(Checkpoint機制),確保系統故障時狀態不丟失、不重復。這是構建可靠實時系統的關鍵。
- 數據流與維表關聯:實時流(行為事件)需要與相對靜態的維表(商品信息、用戶屬性)進行關聯(Join)。Flink提供了多種方式:
- 預加載維表:在算子初始化時加載全量維表到內存,適合小維表。
- 熱存儲查詢:通過異步I/O查詢Redis等外部存儲,適合大維表,但需注意緩存一致性和查詢延遲。
- 時序數據庫關聯:將維表變更也作為流,使用雙流Join。
- 窗口與亂序處理:網絡延遲會導致事件亂序到達。Flink的
Watermark機制允許應用定義最大亂序時間,在窗口觸發計算時,能盡可能包含遲到但合理的數據,平衡了計算的完整性和實時性。 - 系統性能與資源管理:實時推薦對延遲極其敏感(通常要求在百毫秒內)。需要精細調優Flink作業的并行度、網絡緩沖區、狀態后端配置,并合理設置Kafka分區數,確保數據均勻分布,避免數據傾斜導致瓶頸。在Kubernetes或YARN上部署時,需做好資源隔離與彈性伸縮。
- 算法與工程的結合:實時推薦不僅是流處理工程問題,更是算法問題。如何設計低延遲、高效率的實時召回與排序算法,如何將離線訓練的復雜模型(如深度神經網絡)高效地部署到流式計算管道中,并實現特征的實時拼接與對齊,是算法工程師與系統架構師需要緊密協作解決的難題。
五、與展望
基于Flink的商品推薦系統代表了推薦技術向實時化、智能化演進的重要方向。它通過統一的流處理架構,將數據采集、特征計算、模型推理與更新等環節無縫銜接,實現了“數據即產生即處理,模型即反饋即更新”的閉環。這不僅極大地提升了推薦的時效性和相關性,也為探索更復雜的在線學習和強化學習推薦算法提供了強大的系統基礎。
隨著Flink ML庫的完善、與深度學習框架更深的集成(如Alink),以及流批一體技術的成熟,實時推薦系統的構建將變得更加高效和標準化。如何在保障高性能和低延遲的前提下,進一步提升系統的可解釋性、公平性和隱私保護能力,將是學術界和工業界持續關注的前沿課題。
如若轉載,請注明出處:http://m.sdweifan.com/product/29.html
更新時間:2026-05-08 14:13:15